Qyu: A distributed task execution system for complex workflows
Here at FindHotel we build many of our tools in-house and whenever we think that someone can use and benefit from those tools, we release them to the open-source community. This article is about Qyu, a distributed task execution system we built for our advertising campaigns building and marketing software, and how we use it to manage our internal workflows. About two years ago, we were using Resque as a job scheduler for our Ruby services. The application was monolithic, memory-consuming and jobs were always lost in Resque's Redis queue. Resque's workers died abruptly without reliable error reporting, had to be redeployed if we want to change the number of workers on a certain queue and was not supported any longer by the open-source community. We had 10s of services that are used at a variable rate so adding to all the previous problems, we were paying more money for infrastructure that we should. We needed a solution that is reliable, autoscaling and that will help us to break our monolith into microservices.
Qyu is built in Ruby and depends on two basic pieces: a message queue and a state store. By default, as well as for testing purposes, Qyu ships with an in-memory message queue and state store which are definitely not suitable for production purposes. For production usage, we implemented two state stores based on ActiveRecord (for relational databases) and Redis, in addition to two message queues based on Amazon Simple Queue Service (SQS) and Redis. In our production environment, we use the ActiveRecord adapter with PostgreSQL along with the Amazon SQS adapter.
Architecture
State Store
The state store is the persistence layer of Qyu. It has 3 main models:
- Workflow: Used to generate tasks under a job. It describes how a certain program flow looks like.
- Job: A set of tasks running according to a certain workflow.
- Task: Single building block of a job. It has it's payload and own status.
The following is an example of a simple workflow:
descriptor = {
'starts' => %w(
print_hello
),
'tasks' => {
'print_hello' => {
'queue' => 'print-hello'
}
}
}
This workflow instructs the program to start with a task called print_hello and then this task is set to be enqueued in a queue called print-hello. A job using this workflow will have only one task enqueued in the queue.
Message Queue
The message queue component appends task IDs to their respective queues. It provides an organized and fault-tolerant method of dequeuing tasks and ensuring they run successfully before declaring them a success and removing them. An example of the message in a queue is {"task_id": 420}. A listening worker dequeues the message, gets the payload from the state store and starts processing the task.
Usage
Create your first workflow:
Qyu::Workflow.create(name: 'say-hello', descriptor: descriptor)
The above will create a workflow titled say-hello . Now we need to use that workflow by creating a job that follows it. We are gonna create a job with a sample payload as follows. Once you call start on the job, it will create the children tasks in the state store and enqueue the task ID in Qyu's message queue.
job = Qyu::Job.create(workflow: 'say-hello', payload: { 'times' => 5 })
job.start
Now that we have a message in the queue, we need a worker to listen on that queue, consume the message and perform something according to the specified payload. The following worker consumes the messages in the print-hello queue and prints "Hello" a certain number of times that is specified in the payload.
class SimpleWorker
def initialize
@worker = Qyu::Worker.new
end
def run
# Consumes message from print-hello queue
@worker.work('print-hello') do |task|
task.payload['times'].times do |i|
puts "#{i + 1}. Hello"
end
rescue StandardError => ex
# do something
end
end
end
SimpleWorker.run
This worker will this pop a message from the queue and execute the code on it. Output for the above program is the following:
1. Hello
2. Hello
3. Hello
4. Hello
5. Hello
It read a parameter from the payload and used it in the worker. This is a very simple example to how Qyu can be used but there is other great features for Qyu that did not manifest themselves in the above example. One of the most interesting features is the sync workers or sync gates.
Sync Workers
In some use cases, you may need some tasks to finish before starting another specific task that depends on the output of those tasks. This is where Qyu's sync workers become useful. A sync worker can be started as follows:
w = Qyu::Workers::Sync.new
w.work('sync-adgroups')
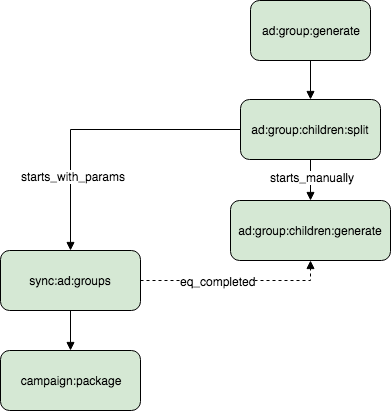
To demonstrate the point, I will give one of our use cases as an example for the sync worker. At FindHotel we use Qyu to manage out campaign building software. We first build empty ad groups, populate those ad groups with ads and keywords and then at the end we package those ad groups into campaigns. The services that generate ads and keywords need to wait for the service that generates ad groups. In the same fashion, the service that packages those ad groups into campaigns need to wait for all of this. The following is out workflow descriptor for this component.
descriptor = {
'starts' => [
'ad:group:generate'
],
'tasks' => {
'ad:group:generate' => {
'queue' => 'ad-group-generate',
'starts' => [
'ad:group:children:split'
]
},
'ad:group:children:split' => {
'queue' => 'ad-group-children-split',
'starts_manually' => ['ad:group:children:generate'],
'starts_with_params' => {
'ad:group:sync:gate' => {
'nr_tasks' => {
'count' => 'ad:group:children:generate'
}
}
}
},
'ad:group:children:generate' => {
'queue' => 'ad-group-children-generate'
},
'ad:group:sync:gate' => {
'queue' => 'sync-adgroups',
'waits_for' => {
'ad:group:children:generate' => {
'condition' => {
'param' => 'nr_tasks',
'function' => 'eq_completed'
}
}
},
'starts' => [
'campaign:package'
]
},
'campaign:package' => {
'queue' => 'campaign-package',
}
}
}
Notice the ad:group:sync:gate in sync-adgroups queue which waits for all ad:group:children:generate tasks to finish successfully before starting the dependent campaign:package task. Once the number of spawned tasks is equal the number of completed tasks; campaign packaging starts. So whenever there is a need to optimize code runtime and flexibility, Qyu is useful to paralellize some parts of the workflow and get a single output in the end. You can deploy multiple workers in Docker containers and scale some up/down according to load at any certain point in the workflow. For example we have 1 docker container for campaign-package since it is a simple task that should not be parallelized but we generate ads and keywords under ad groups via multiple docker containers.
To conclude, Qyu is very useful to us and we love it. We released it to the open source community to further improve it and hoping that it will help other developers build distributed systems. Feel free to submit issues or PRs at https://github.com/QyuTeam/qyu.
